Getting Started Guide: NFO
This Guide provides step-by-step instructions for installing and configuring a basic deployment of NetFlow Optimizer. You'll learn how to set up flow data inputs, outputs, and configure NFO Modules to process your flow data effectively.
Requirements for NFO
OS
NFO could be deployed on most Linux ODs (Linux kernel 2.17+) or on Windows (Windows Server 2012 R2, 2016, 2019, 2022)
System
These are the minimum requirements for an NFO deployment (virtual machine or physical server):
- 2 physical CPU cores or 4 vCPU at 2Ghz or greater speed per core
- 8GB RAM
- 20GB disk space
Supported Browsers
You can use one of the following browsers to connect to the NFO Web user interface.
- Mozilla Firefox 38.0 and up
- Safari 6.0, 7.0
- Google Chrome 34.0 and 43.0 and up
- IE10, IE11, and MS Edge
Required Network Ports
The following network ports must be accessible.
| Port | Description |
|---|---|
| 8443/TCP | NetFlow Optimizer GUI |
| 9995/UDP | NetFlow/IPFIX Ingestion (plus all ports for ingestion as necessary) |
| 161/UDP and 162/UDP | SNMP polling and SNMP traps |
| 9001/TCP | Configuration Data Base, port is opened on loopback interface 127.0.0.1 |
| 20047/TCP and 20048/TCP | NetFlow Optimizer internal services, ports are opened on loopback interface 127.0.0.1 |
| 20047/UDP and 20048/UDP | NetFlow Optimizer outputs for Kafka, OpenSearch, etc., ports are opened on four loopback interfaces 127.17.0.1 - 127.17.0.4 |
Download and Install NFO
You should install and run NFO as as root for Linux and administrator for Windows.
Download the latest version of NetFlow Optimizer at: https://www.netflowlogic.com/downloads/
To install NFO on your platform, visit NFO Installation Guide.
Upon successful installation a message will display indicating that the NetFlow Optimizer installation has been successfully completed.
Log in to NetFlow Optimizer at https://<nfo-host>:8443 where NFO‑host is the IP address or host name of the NFO server, apply license, and continue configuration.
Get NetFlow Flowing
Add Inputs
By default NetFlow Optimizer is preconfigured with one active data input UDP port number 9995. You may change it or add additional ports. For more information on inputs, including configuration for ingesting cloud flow logs, visit Configure Inputs.
Add Outputs
You may add up to sixteen output destinations, specifying the format and the kind of data to be sent to each destination. For more information on outputs, visit Configure Outputs.
Configure NetFlow Processing Modules
By default, NetFlow Optimizer comes preconfigured with one enabled module, the Top Traffic Monitor. This module is capable of processing various types of flow data, including NFv5/v9, sFlow, JFlow, IPFIX, and cloud flow logs. It generates consolidated unidirectional flow data enriched with host names or DNS names.
Alternatively, you can enable the Network Conversation Monitor. This module also supports processing different types of flow data and can be configured to "stitch" flows, reporting bidirectional network conversations. Additionally, it offers various enrichment options, such as VM or cloud instance names, applications, user identity, security reputation, and Geo IP.
SNMP Polling and Traps
NetFlow Optimizer comes with flexible support for SNMP polling and Traps. To learn more, visit Getting Started Guide: SNMP Polling.
Plan for Production
There are several key factors to consider that will determine the type of NFO deployment in your environment:
- The amount of NetFlow data you'd like to process from your network devices on premises
- The number of data centers or geographical locations of your offices with network equipment you'd like to monitor
- Whether you have on prem, cloud, or hybrid environments
- In case of cloud or hybrid environments, whether you want to collect VPC Flow logs to monitor your entire infrastructure
- Location of your SIEM (on prem or in the cloud) and other systems you'd like to store flow data for full fidelity or compliance
To learn more about NFO High Availability, see High Availability Deployment.
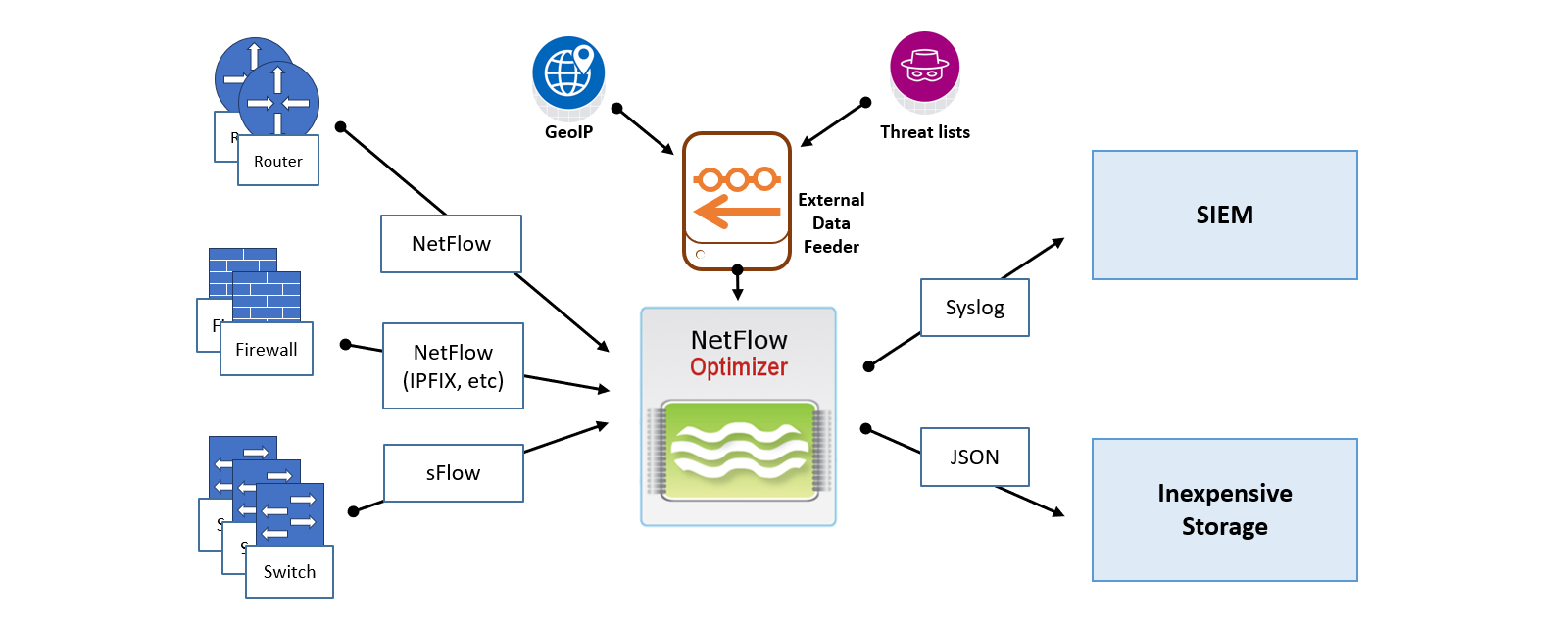
Single Instance Deployment
In this scenario, one instance of NetFlow Optimizer handles all flow data processing, enrichment, and SNMP polling. A single-instance deployment can be useful for evaluation purposes and might be sufficient to serve the needs of small to medium size organizations.
Distributed Deployment on Premises
Consider this scenario if you have multiple data centers or remote offices, or if you'd like to apply different rules (NFO configurations) to different group of devices (e.g. collect all flows from edge devices, and only top traffic from internal switches). In these scenarios you may still choose to receive flow data in a central SIEM or in a SIEM deployed in your cloud.
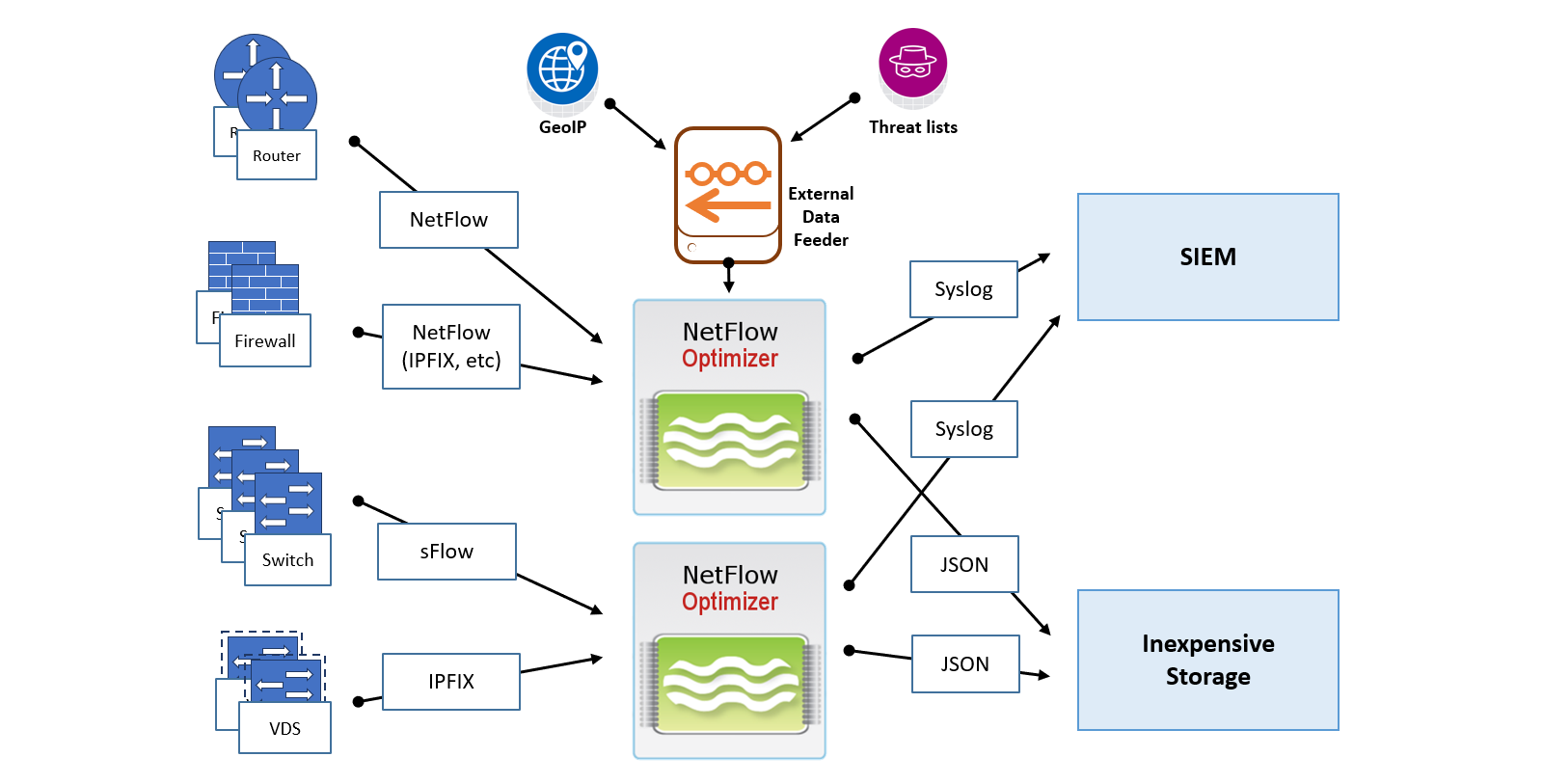
You may also choose the following scenario.
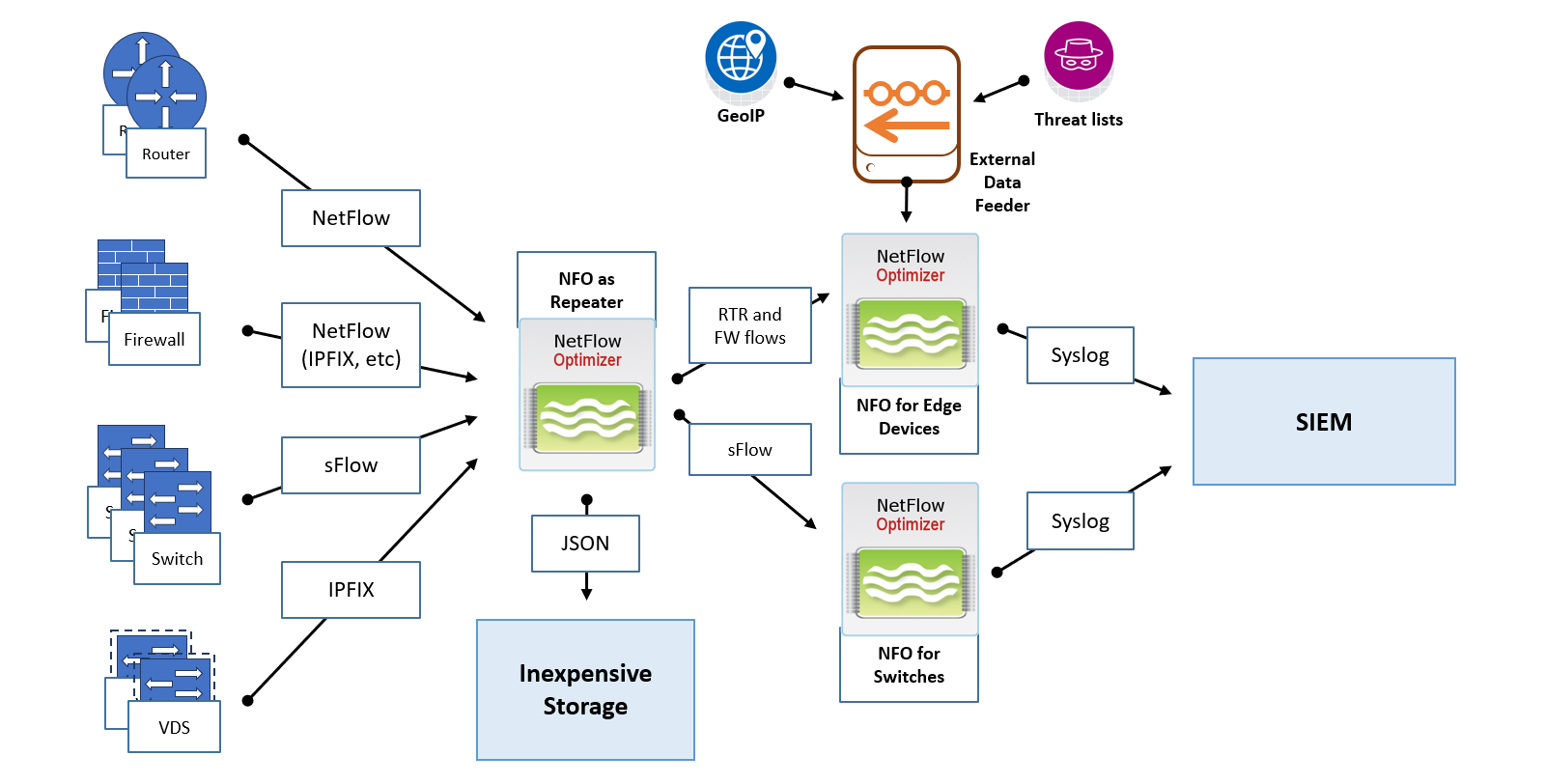
In this deployment, you dedicate one NFO instance as a central point for collecting flows from all your network devices. This instance is configured in Repeater mode, with optional full fidelity flow data recording. The NFO Repeater functionality allows you to retransmit the original flow data to other destinations, specifically other NFO instances. This setup enables flows from certain devices (e.g., routers and firewalls) to be sent to NFO instance 2, where NFO Logic Modules with configurations for routers and firewalls are enabled. Likewise, flows from other devices (e.g., switches, VDS) are sent to NFO instance 3, where NFO Logic Modules suitable for processing flows from switches are enabled.
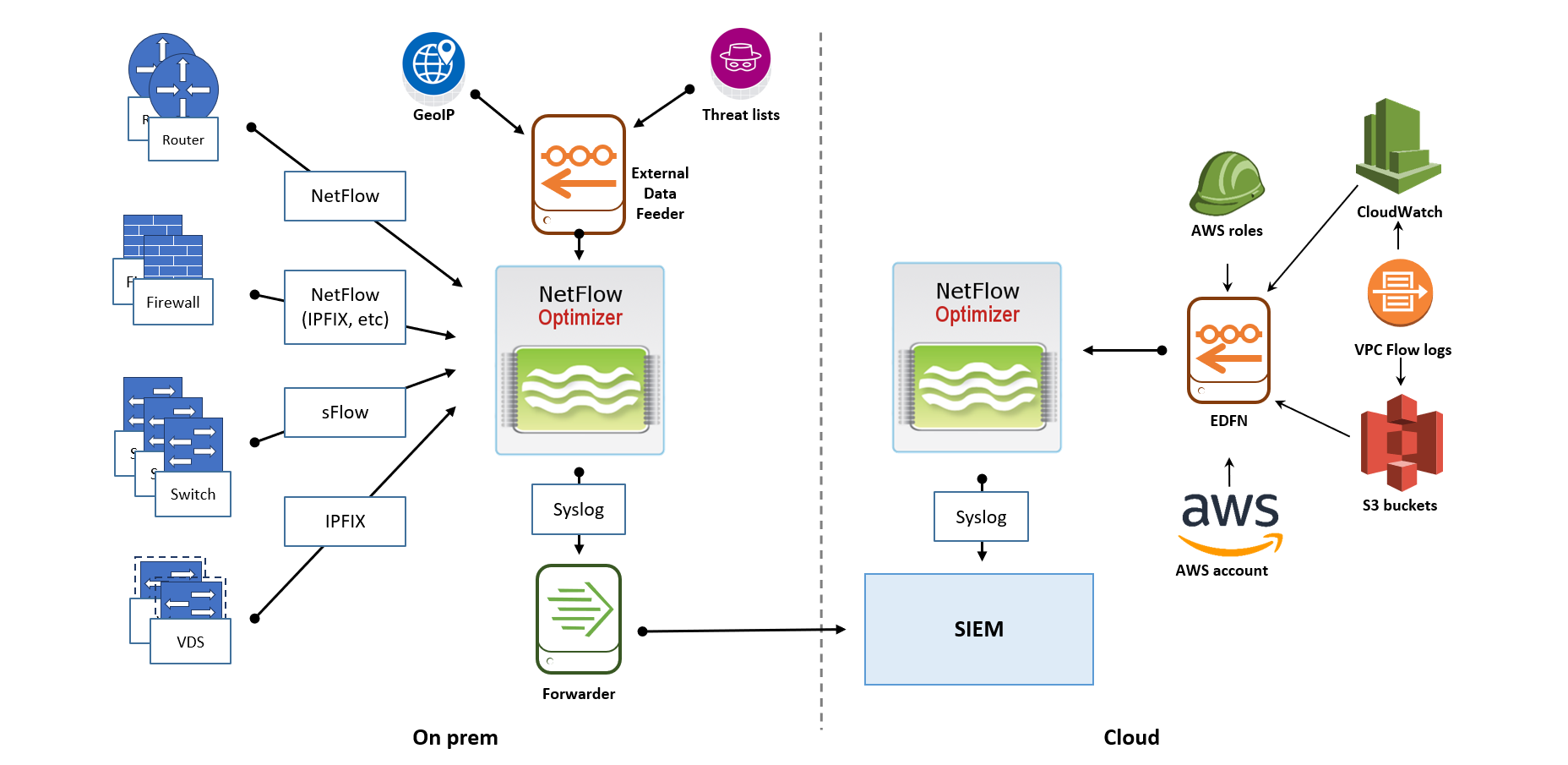
Distributed Deployment in Hybrid Environment
Consider this scenario if you have your own data center with SIEM installed on premises, and you'd like to collect flows from your physical devices and VPC Flow logs from your cloud.
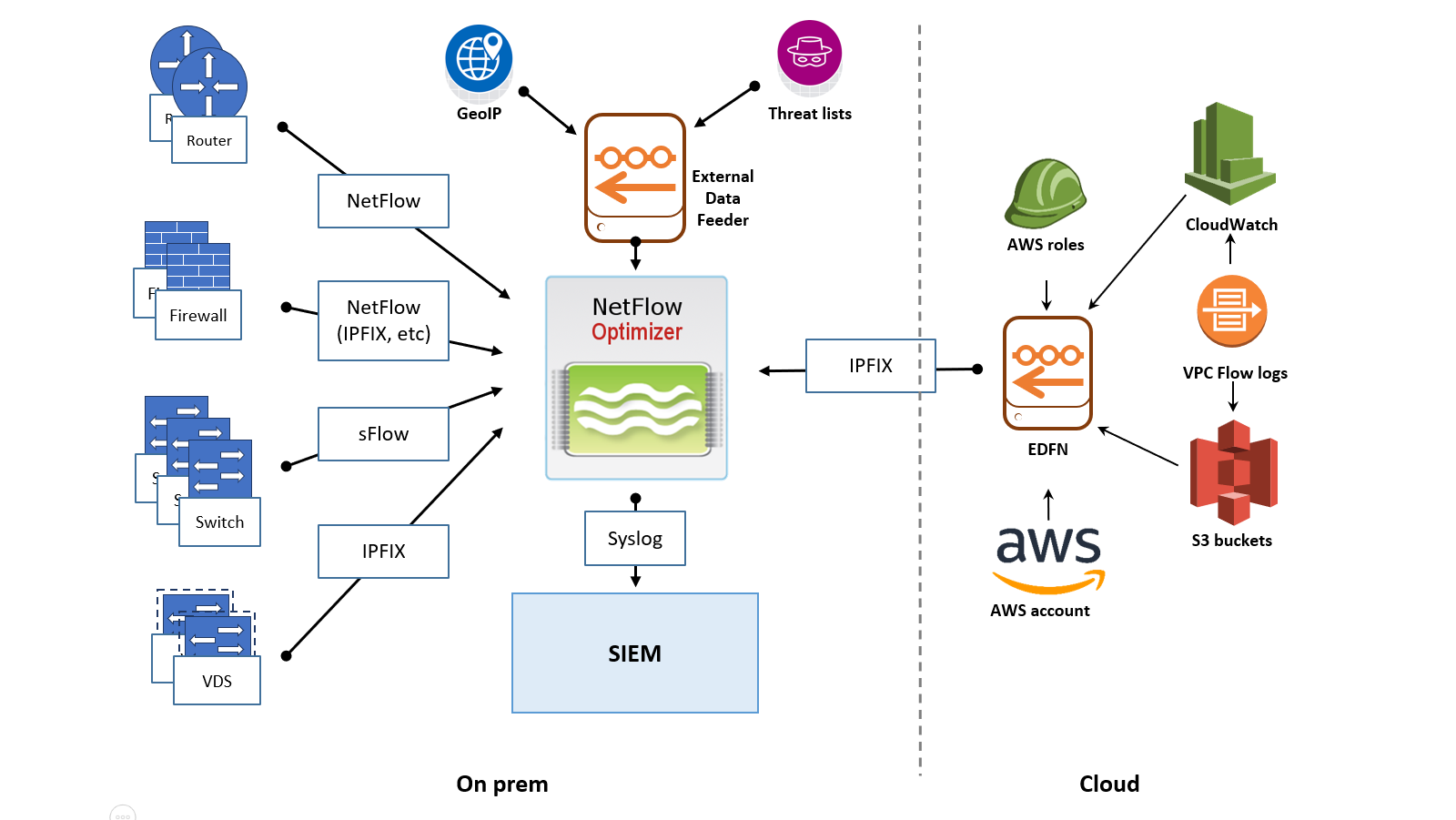
If your SIEM is running in the cloud, here is an example of recommended deployment.